让 AI 当裁判这件事——提示词怎么调试,能不能让它自己进化
用大模型给另一个模型的输出当裁判(LLM-Judge)时,判定提示词需要持续校准。借助 AI 协作已经能把单轮调试做得更稳,但一旦真正自动运行,过拟合评测集、无节制重写、成本失控、规则膨胀都会出现。本文借微软 SkillOpt 论文和开源工具的思路,聊聊如何把裁判提示词迭代设计成一套有约束、可验证、能持续滚动的流程。

最近做 LLM-Judge 的时候,最常遇到的情况是:模型对这批样本能够判对,但换一批样本又不稳定。
以前做测试,流程相对简单。返回值对不对、格式齐不齐、状态码是不是 200,写几行程序一跑就知道,对就是对,错就是错。
但换到大模型这边,麻烦就来了。“这段回答有没有跑题”“有没有胡编乱造”“逻辑链断没断”——这些问题写不出明确规则,你没法用 if-else 来判断“是否跑题”。
于是有了个办法:再找一个大模型来当裁判,让它读一遍输出,判断这次回答到底好不好。这就是 LLM-Judge(用大模型当裁判)。
但裁判也是模型,它自己也会看走眼。要把这个裁判调试到足够准、足够稳,关键在于持续校准那份判定提示词。本文想聊的有三件事:裁判提示词怎么一轮轮调试出来,调到后面会卡在哪,以及怎样把这套流程设计成可持续自动迭代的形态。
研测一体:没有评测集,调试就只能靠感觉
调试裁判之前,先要有一把尺子。
你改了裁判的提示词,它判得比之前准还是更糟?光凭感觉是答不上来的,因为今天看着顺眼,明天换一批数据可能就失效了。
这把尺子就是评测集——一组事先标好“该判过 / 该判不过”的题。改完提示词,拿这套题跑一遍,分数有没有提升、有没有回退,都能及时看见。原本“我觉得好像准了点”,变成“73 分涨到 85 分”。
这个理念我在之前那篇《Agent 产品的“牵一发而动全身”》里也提到过:任何跟大模型相关的研发,都得配一套评测集。没有它,你根本不知道每次改动是往前还是往后。评测集的作用,就是把质量变化变成可观察的数字。
有人可能想,人工抽几条看看不就行了?看十条八条确实没问题。可你改一句提示词,很可能修好了眼前这三条,同时让另外五条悄悄出错。评测集就是来帮你覆盖这些盲区,确保问题不会被少量样本掩盖。
一句话的改动,也可能改变整体行为
提示词的敏感性很高,哪怕改动很小,效果也很可能会明显波动。
Claude Code 出过一个很典型的例子。他们为了提高回复速度,压缩了工具调用的回复长度,在 Prompt 里加了一句“工具调用之间,话别超过 25 个词”。这个改动听着像个无害的小优化,但结果却导致模型把一些对下一步最有用的推理铺垫也一起压缩掉了,进而对于复杂任务来说,就开始表现为流程绕路、任务无法完成。简单说,就是它的行为边界发生了偏移。(这个问题我在上一篇细聊过。)
裁判这边也一样。你以为多写几条判定规则,裁判会更准。但很可能就因为这几个规则,导致在某些边界被有机可乘,所以加规则反而会拖后腿。
后面会提到的那篇论文里,就有组数据特别说明问题。同样是给模型配一份“人工写的技巧文档”,有的任务能涨三十多分,有的任务却直接掉分(表格里一片红色的负号)。一模一样的做法,换个场景可能就是两个结果。
所以提示词不能只靠堆规则。每改一次,都得拿评测集重新称量:这次改动到底是在补边界,还是在制造新的偏差。
一个裁判是怎么调试出来的
举个例子,假设要做一个裁判,专门看“AI 的回答有没有跑题”。
先把评测集定下来。 把“什么算跑题、什么不算”这些边界固定清楚。这一步可以让 AI 先生成一版初稿,人再上手标注、调整边界。这一步定的是基调——后面所有调试,都围着这套题转。
写裁判程序。 核心是一段判定提示词,外围再加上模型调用和结果解析的封装层。不同裁判的区别,主要就在提示词怎么写。
跑评测、看错题、再验证。 把评测集交给裁判程序运行,看当前得分。挑出判错的题,连同“它为什么判错”一起交给 AI,让 AI 分析原因、修改提示词。改完再跑一遍。
最后这一步要持续迭代,直到评测集达到预期标准。
flowchart TD
A["把评测集定下来<br/>(什么算跑题先圈清楚)"] --> B["写裁判程序<br/>(一段提示词 + 模型调用封装)"]
B --> C["拿评测集跑一遍,看当前得分"]
C --> D{"达到预期了吗?"}
D -->|未达到| E["挑出判错的题<br/>连同“为什么错”交给 AI"]
E --> F["AI 分析,改提示词"]
F --> C
D -->|达到| G["上线"]
G --> H["生产环境沉淀真实案例"]
H --> I["人工标注,扩大评测集"]
I --> C上线之后还没完。裁判在生产环境持续运行后,会沉淀出一批真实案例。人工再标一批,把评测集扩大。评测集一变大,又得重新调试、重新验证,通过后才发布新版本。
这个循环会持续存在。循环里最花精力的那一环——看错题、分析为什么错、动手改提示词——基本都需要人在中间把关。
几个调试的小技巧
分享几个我在改写提示词时候的小技巧:
把反复要交代的内容做成 Skill。 每次让 AI 帮你分析错题、改提示词,都要先交代背景、判定规则和历史边界。可以把这些内容固化成一份说明文档(也就是 Skill),下次直接作为上下文复用,减少重复沟通。
让裁判先找差异,再下结论。 直接问裁判“这条过不过”,它很容易顺着第一印象走:先给出结论,再为这个结论强行找理由,哪怕理由是错误的。这就是确认偏误。也是因为这个,诞生了模型的”思考模式“,所以,我们可以设置模型的返回内容先是输出分析,再输出结论,也就是换个位置:列出“实际输出比标准答案差在哪”,把差异一条条摆出来,最后才判过不过。
这个做法借的是模型的自回归特性——模型是一个字接一个字往下写的,后面的输出会受前文影响。前面已经列出明确差异,后面再写“通过”,就会形成明显冲突。结论因此被前面的证据约束住。
让AI找出具体原因,再做修改。 比如我们评测之后有了一些badcase,然后我们就可以让AI分别找出”导致这个badcase发生的那句话”以及”预期会正确判断的那句话”,然后再结合”模型判断时候输出的分析内容”,三者叠加去让AI微调提示词。因为这样可以更精确地定位问题,避免模糊的修改。
这些做法叠加起来,单轮调试会稳定很多。但它们解决的只是”单轮怎么改得更好”,还没有解决”能不能让整个迭代循环自动运行”。
让 AI 自己改,会遇到哪些风险
到这儿,改提示词已经接近半自动:人负责看错题和把关,AI 负责分析原因、起草补丁,再通过评测验证。
那能不能再进一步,让人少介入一点?让它定期自己看错题、改提示词、跑验证,最后只把结果交给人 review。
思路很自然,但真正自动运行后,风险会集中暴露。
它会过拟合评测集。 如果优化器只盯着错题改提示词,很容易把评测集里的标准答案、关键词或样本特征写进规则里。分数看起来涨了,实际学到的是对这批题的记忆,判定能力没有真正提升;换一批没见过的数据,问题就会暴露。虽然可以强行添加提示词规则限制,但是也很难保证模型会不会出现幻觉而不遵循规则。
它会无节制重写。 为了修眼前几道错题,优化器可能把原本有效的规则一起改掉,或者新增一条只适用于少数样本的窄规则。下一轮分数掉了,它再继续大改,提示词就会越来越不稳定。
它会消耗失控。 如果没有验收门和停止条件,优化器可能在低收益方向上连续尝试很多轮。每一轮都要调用模型、跑评测、分析失败原因,成本持续累积,指标却没有实质提升。
它会让规则膨胀。 改着改着,提示词越来越长、越来越乱,前后两条规则互相冲突,最后没人看得懂它到底想让裁判怎么判。
说到底,自动迭代卡住的关键,不在于该人改还是该模型改。人当然可以继续靠经验看错题、改提示词、跑评测。问题出在自动流程缺少约束:没人防过拟合,没人限制大幅改写,没人及时拦住无效方向,失败经验也很难沉淀下来。
不过最近有篇论文,正好给了一套可参考的答案。
SkillOpt:一套可参考的自动优化思路
微软联合几所高校发表了一篇论文:SkillOpt: Executive Strategy for Self-Evolving Agent Skills。微软也开源了 microsoft/SkillOpt,这个开源框架已经有 PyPI 包、训练和评估脚本、Gradio WebUI,以及面向 Claude Code、Codex、Copilot 的 SkillOpt-Sleep。后面设计裁判自动迭代流程时,我会参考它的工具形态和约束机制。
我关注它的原因很直接:它刚好踩中了前面那个问题。让 AI 改提示词并不难,难的是别让它越改越歪。
论文优化的是 agent 的 skill——一份外挂给模型的“做事说明书”。模型权重一个字不动,只通过修改这份文档,把模型在某个任务上的表现一点点提上去。论文对象是 agent skill;放到裁判场景里,我借的是它的受限编辑、验证门、失败记录和慢更新这套机制,要改的“说明书”就是那份判定提示词(但 skill 其实也是提示词)。
它的核心想法就是:把 skill 文档当成冻结模型的外部可训练状态,像训练神经网络那样训练这份文档,每一步都有约束、有验证。
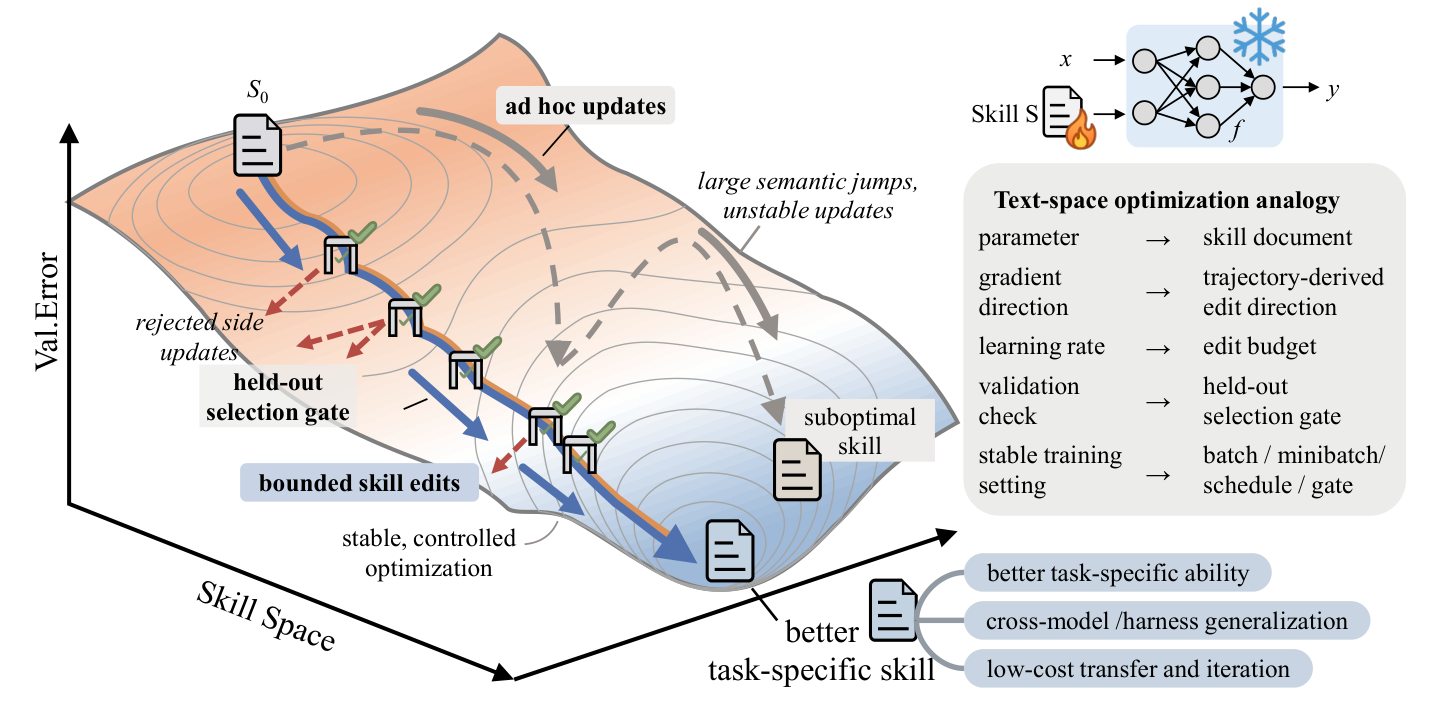
这张图把核心关系说清楚了。把所有可能的文档想象成一片地形,高处判得差、低处判得好,目标是走到谷底。临时乱改(图里灰色的 ad hoc updates),就像在地形上凭感觉跳步,步子过大容易越过更优区域,停在一个不够好的位置。SkillOpt 换了种走法:每步只迈一小段,迈之前还设一道验证门,分数没有真正变好就不能进入下一轮。右边的对照表更直接,把整套机制跟训练神经网络一一对上——要调试的“参数”就是那份文档,“学习率”就是一次允许改几处,“验证”就是那道门。
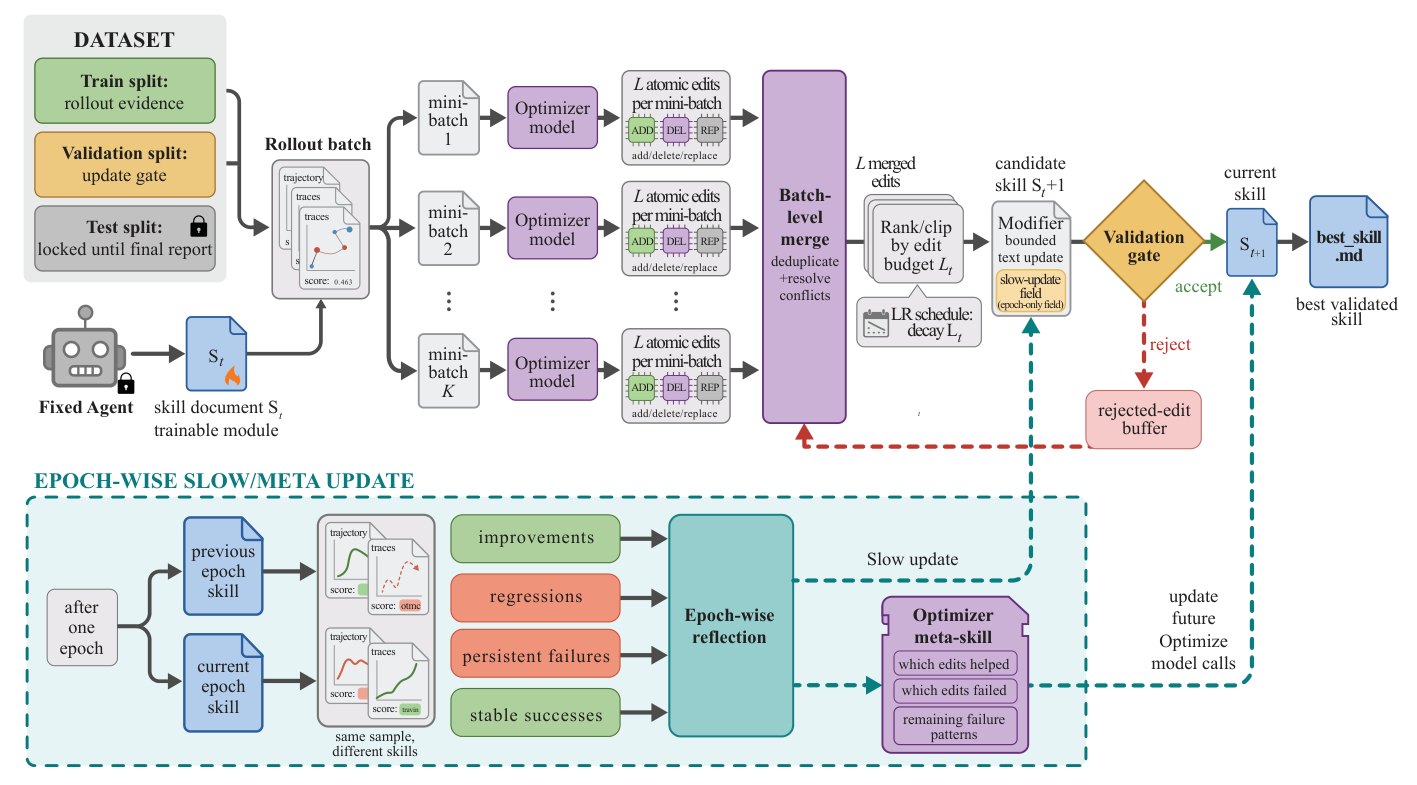
仓库里的训练流程更具体:rollout、reflect、aggregate、select、update、evaluate。训练阶段会反复跑任务、分析轨迹、生成候选编辑、过验证门;最后产出一份 best_skill.md。部署时只加载这份文档,不额外调用优化器模型。
实验结果也支撑这个方向。它在 6 个 benchmark、7 个目标模型、3 种执行环境上做评估,52 个组合全部拿到最好或并列最好。拿 GPT-5.5 来说,相比“不给文档”的 baseline,direct chat、Codex agentic loop、Claude Code 三种环境平均都有接近二十到二十多分的提升。我主要借它的几道流程约束,来处理前面提到的几类风险。
几个可以直接借鉴的约束
一、评测集切三份,只让优化器看 train——防过拟合
它把评测集切成三份:一份(train)拿给优化器看错题、提改动;一份(validation)专门做验收;最后一份(test)锁起来,全程不碰,只在最终报成绩时使用。
为什么有用?还记得前面那个“把答案抄进提示词”的问题吗?现在优化器从头到尾只看得到 train。它就算把 train 里的样本特征写进提示词,验收用的是没见过的 validation,最终评估用的是锁住的 test——单纯记忆样本,很难同时通过后两道关。
落到裁判上:优化器最多只能基于 train 那批判例提改动。可决定提示词能不能更新、最后到底准不准的,是它没碰过的另外两份。这样才能避免把“记住样本”误当成“学会判断”。甚至裁判提示词上有了这些 case 作为 few-shot 反而可能效果或更好。
二、给改动设“预算”,一次只动几处——控制无节制重写
它给每一步的改动定了个上限,论文里叫编辑预算(edit budget),对应训练里的“学习率”——一次最多改几处,不能推倒重写。候选编辑也被限制在 add、delete、replace 这几类操作里,优化器不能直接重写整份文档。而且这个改动预算还会逐轮收紧:前期多试几处,后期只做小修小补。
为什么有用?因为大改正是提示词不稳定的根源。一次只准动几处,它就没法把原来管用的规则成片删掉,也很难塞进一条只服务于少数样本的窄规则。论文里有个数据很说明问题:最后真正被采纳、写进文档的改动,通常只有 1 到 4 处,却能换来几十分的提升。改得少,反而改得准。
落到裁判上:给优化器明确“一次最多动 N 条判定规则”,提示词就不会在一轮迭代里被大幅改写。出了问题,也更容易定位是哪一处改动带来的影响。
三、改完先过验证门,分数严格提升才接受——拦住无效改动
每生成一版补丁,先拿验证集(前面划出来做验收的那份)跑一遍。分数严格提升,才接受这版当新起点;没有提升,哪怕只是打平,也直接回滚。论文里管这叫验证门(held-out validation gate)。
为什么有用?这把“AI 自己说改得好”变成了“拿数据证明改得好”。优化器可以把改动分析得很完整,但落到真实模型上是否有效,验证集说了算。这就是所谓的“先提方案,再用数据拍板”(propose-and-test)——优化器负责提案,验证集负责拍板。
它还顺带控制了成本。每一步要么提升、要么回滚,流程不会在一个错误方向上连续推进。再配合优化器优先处理“成片出现的系统性错判”,少为边角个例反复试探,token 消耗也会收敛得多。
落到裁判上:judge-prompt 每生成一版补丁,都得先过验证集这道门,通过后才更新。线上那个裁判,永远用的是验证过、确实更准的那版。
四、沉淀试错记录——抑制规则膨胀,避免重复无效修改
它会记录优化过程里的失败经验。被验证门拒掉的改动,连同“这么改掉了多少分”,都记下来(论文叫 rejected-edit buffer,被拒改动缓冲);跨轮次发现的长期规律,单独沉淀进文档里一块受保护、快改动碰不到的区域(慢更新)。下次提改动前,先检查这些记录,避免重复提交类似的无效改动。
光记录还不够,它还给优化器制定了一套“改提示词的规矩”(论文附录里写得很细),基本可以直接迁移:
- 改动必须能泛化,不准把某条具体样本的答案、关键词写死进提示词。
- 只补提示词缺的那块,别把已经写过的话再说一遍。
- 先修判错的;判对的样本只用来“别把对的改坏”,不轻易加新规则。
- 排序时优先修“成片出现的系统性错判”,别为一个边角个例大动干戈。
为什么有用?前面说的规则膨胀,本质上是缺少约束:规则越写越多,却没有边界和优先级。有了这套规矩加历史记录,提示词只会往“缺什么补什么”的方向长,不会越改越臃肿。被拒的改动也会沉淀成负面经验,反过来提醒下一轮别再这么改。
我们的裁判自动迭代架构
我设计的结构是:把上面几个约束组合成一套线上线下分离的自动迭代流程。几个角色的对应关系如下:
- 论文里冻住的“执行模型”,对我们就是裁判模型本身(不动);
- 论文里训的那份 skill 文档,对我们就是裁判的判定提示词(judge-prompt);
- 论文里一道道任务,对我们就是一条条判定样本;
- 论文里的得分,对我们就是“裁判判得跟人工标注一致的比例”。
评测集不必从零开始积累。裁判在生产环境持续运行后,会自然沉淀出一批真实判例。挑那些“裁判判定和人工复核不一致”的样本重新标注,就是最有价值的错题来源。按论文那样切成三份,线上运行时间越长,数据覆盖面越完整,也越能暴露边界情况。
整套流程要做线上线下分离。线上裁判照常工作,不增加额外模型调用,时延和成本不变;优化器只在线下运行,负责看错题、提出补丁、跑验证。
flowchart TD
subgraph online["线上:裁判照常工作"]
J["裁判模型 + judge-prompt"] --> R["判定结果"]
R --> P["挑出可疑判例<br/>(跟人工复核不一致)"]
end
P --> L["人工标注入库<br/>切成 train / 验证 / test 三份"]
subgraph offline["线下:优化器自动调试"]
L --> O["优化器只看 train 错例<br/>按“改提示词的规矩”提出补丁"]
O --> CLIP["按编辑预算压缩到少量改动"]
CLIP --> G{"验证集通过?<br/>分数是否严格提升"}
G -->|提升| U["更新 judge-prompt<br/>记录有效改动"]
G -->|未提升| B["回滚<br/>记录无效改动"]
B --> O
U --> M["阶段性沉淀长期规律<br/>(慢更新,受保护)"]
M --> O
end
M --> T["最后用锁住的 test 集验收"]
T -->|确实更准| J线上裁判照常判,把那些跟人工复核不一致的判例挑出来,人工标好答案,切三份入库。线下,优化器只读取 train 那份错例,按规矩提出补丁,并压缩到编辑预算之内;验证集分数严格提升,才更新提示词并记录有效改动;没有提升就回滚,并记录这类无效方向。运行几轮后,把长期规律沉淀到受保护的区域;最后拿全程锁住的 test 集验收,确认确实更准了,才把新提示词推回线上。
前面那四类风险,到这里都有了对应的约束:三份数据防过拟合,编辑预算限制无节制重写,验证门拦住无效改动,历史记录和改写规则抑制规则膨胀。原先由人坐在中间看错题、改提示词的工作,被拆成了一套可验证、可回滚、可沉淀的流程。
SkillOpt 已经开源,能提供训练框架和设计参考;裁判场景仍然要补齐自己的工程接口:评测样本切分、人工标签沉淀、judge score 定义、线上判例回流。我的这版架构也还停在初步设计阶段。真正落地时,还要继续验证裁判的好坏判断怎么定、人工标注成本怎么摊、多久迭代一轮才划算。论文也提醒过,偏主观任务的验证门可能需要更强的人工或模型把关。
写在最后
最后落到两件事。
裁判判得准不准,得有评测集这把尺子兜底,否则就只能停留在自我感觉。提示词怎么调试,眼下还是人带着 AI 看错题、改提示词、跑评测;想往全自动走,关键在于给自动流程补上约束:防过拟合、控步长、过验证门、记录失败经验。
SkillOpt 给的就是这样一套模板:验证集负责验收,编辑预算控制步长,失败记录提供记忆,慢更新沉淀长期规律。调试提示词这件事,只有被这些机制约束住,才有机会从经验试错,变成一套能解释、能复盘、能自己滚动的流程。
往后只要把生产环境的判例积累起来、标注清楚,让模型有节制地改、拿分数把关,调试裁判这件事,确实有机会从长期人工盯守中解放出来。